杠杆炒股,股票融资!

发布日期:2025-02-20 08:53 点击次数:127
AIxiv专栏是机器之心发布学术、时刻现实的栏目。往日数年,机器之心AIxiv专栏摄取报说念了2000多篇现实,遮掩寰球各大高校与企业的顶级实验室,灵验促进了学术疏通与传播。要是您有优秀的使命念念要共享,宽饶投稿或者筹商报说念。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
Ola 是腾讯混元 Research、清华大学智能视觉实验室(i-Vision Group)和南洋理工大学 S-Lab 的合营名堂。本文的共同第一作家为清华大学自动化系博士生刘祖炎和南洋理工大学博士生董宇昊,本文的通信作家为腾讯高档策动员饶永铭和清华大学自动化系鲁继文讲明。
GPT-4o 的问世激发了策动者们对好意思满全模态模子的浓厚兴趣兴趣。尽管目下如故出现了一些开源替代决议,但在性能方面,它们与挑升的单模态模子比拟仍存在明显差距。在本文中,咱们忽视了 Ola 模子,这是一款全模态讲话模子,与同类的挑升模子比拟,它在图像、视频和音频衔接等多个方面都展现出了颇具竞争力的性能。
Ola 的中枢狡计在于其渐进式模态对皆战略,该战略逐步扩展讲话模子所撑捏的模态。咱们的查察历程从各别最为显贵的模态动手:图像和文本,随后借助伙同讲话与音频学问的语音数据,以及伙同统共模态的视频数据,逐步拓展模子的技巧集。这种渐进式学习历程还使咱们梗概将跨模态对皆数据保管在相对较小的规模,从而让基于现存视觉 - 讲话模子开发全模态模子变得更为肤浅且本钱更低。

名堂地址:https://ola-omni.github.io/
论文:https://arxiv.org/abs/2502.04328
代码:https://github.com/Ola-Omni/Ola
模子:https://huggingface.co/THUdyh/Ola-7b
Ola 模子大幅度鼓吹了全模态模子在图像、视频和音频衔接评测基准中的才智上限。咱们在涵盖图像、视频和音频等方面的齐备全模态基准测试下,Ola 手脚一个仅含有 7B 参数的全模态模子,好意思满了对主流独有模子的特出。
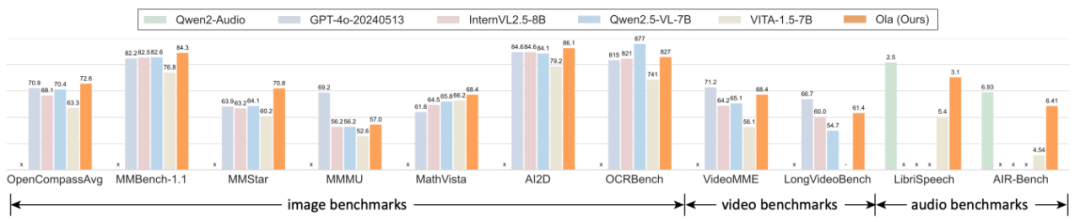
图 1:Ola 全模态模子特出 Qwen2.5-VL、InternVL2.5 等主流多模态模子。
在图像基准测试方面,在极具挑战性的 OpenCompass 基准测试中,其在 MMBench-1.1、MMMU 等 8 个数据集上的总体平均准确率达到 72.6%,在市面上统共 30B 参数以内的模子中排行第 1,特出了 GPT-4o、InternVL2.5、Qwen2.5-VL 等主流模子。在详尽视频衔接测试 VideoMME 中,Ola 在输入视频和音频的情况下,取得了 68.4% 的准确率,特出了 LLaVA-Video、VideoLLaMA3 等驰名的视频多模态模子。另一方面,Ola 在诸如语音识别和聊天评估等音频衔接任务方面也通晓突出,达到了接近最喜信频衔接模子的水平。
齐备的测试截止标明,与现存的全模态大讲话模子(如 VITA-1.5、IXC2.5-OmniLive 等)比拟,Ola 有稠密的性能提高,致使特出了起先进的独有多模态模子的性能,包括最新发布的 Qwen2.5-VL、InternVL2.5 等。目下,模子、代码、查察数据如故开源,咱们旨在将 Ola 打酿成为一个统共开源的全模态衔接处罚决议,以鼓吹这一新兴规模的将来策动。
1. 先容
查察全模态大模子的中枢挑战在于关于多种散播的模态进行建模,并狡计灵验的查察历程,从而在统共撑捏的任务上好意思满存竞争力且平衡的性能。然则,在以往的策动中,高性能与粗犷的模态遮掩经常难以兼顾,现存的开源全模态处罚决议与起先进的专用大讲话模子之间仍存在较大的性能差距,这给全模态认识在现实天下的应用带来了严重间隔。
在本文中,咱们忽视了 Ola 模子,探索如何查察出性能可与起先进的专用多模态模子相失色、具备及时交互才智且在对皆数据上高效的全模态大讲话模子。Ola 模子的中枢狡计是渐进式模态对皆战略。为在讲话与视觉之间拓荒筹商,咱们从图像和文本这两种基础且相互孤独的模态动手,为全模态模子构建基础学问。随后,咱们逐步延伸查察集,赋予模子更粗犷的才智,包括通过视频帧强化视觉衔接才智,借助语音数据连通讲话与音频学问,以及阁下包含音频的视频全面交融来自讲话、视频和音频的信息。这种渐进式学习战略将复杂的查察过程理会为小法子,使全模态学习变得更容易,从而保捏较小规模的跨模态对皆数据,也更容易基于视觉 - 讲话模子的现存截止伸开策动。
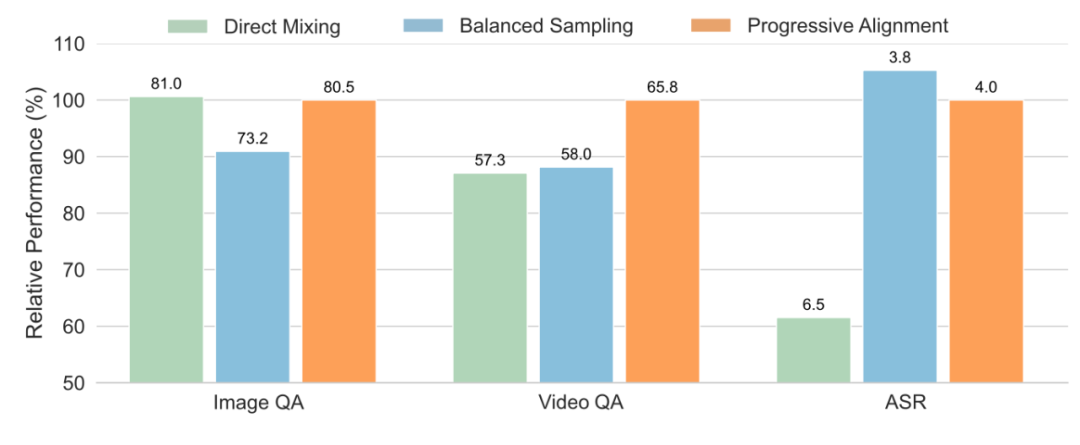
图 2:渐进式模态学习梗概查察更好的全模态模子
为配合查察战略,咱们在架构和数据规模也进行了伏击校正。
Ola 架构撑捏全模态输入以及流式文本和语音生成,其架构狡计可扩展且直快。咱们为视觉和音频狡计了荟萃对皆模块,通过局部 - 全局严防力池化层交融视觉输入,并好意思满视觉、音频和文本标识的解放组合。此外,咱们集成了逐句流式解码模块以好意思满高质地语音合成。
除了在视觉和音频方面聚集的微调数据外,咱们潜入挖掘视频与其对应音频之间的关系,以构建视觉与音频模态之间的桥梁。具体而言,咱们从学术及绽开式聚集资源聚集原始视频,狡计孤独的计帐历程,然后阁下视觉 - 讲话模子证明字幕和视频现实生成问答对。
2. 行径概览
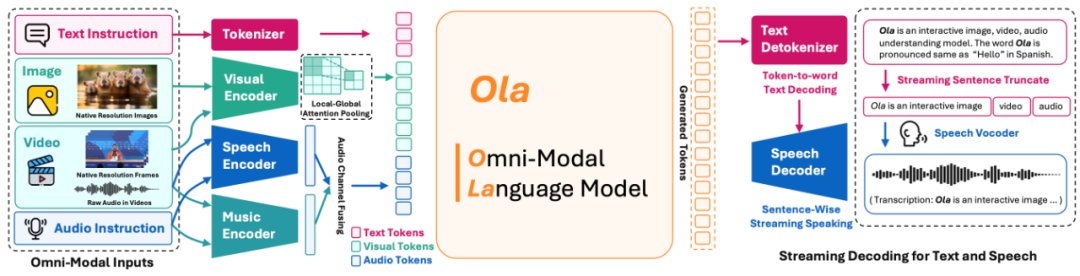
图 3:Ola 模子结构图
全模态结构狡计
全模态输入编码:基于先前文本到单模态大讲话模子的得手履行,咱们别离对视觉、音频和文本输入进行编码。关于视觉输入,咱们使用淘气分辨率视觉编码器 OryxViT 进行编码,保留每个图像或帧的原始宽高比;关于音频输入,咱们忽视双编码器行径,使用 Whisper-v3 手脚语音编码器,BEATs 手脚音乐编码器;关于文本输入,咱们径直使用预查察大讲话模子中的镶嵌层来处理文本标识。
视觉与音频荟萃对皆:对皆模块充任从特定模态空间到文本镶嵌空间的退换器,这是全模态大讲话模子的要津部分。为了提高效力并减少视觉特征的标识长度,咱们进一步忽视了 “局部 - 全局严防力池化” 层,以在减少信息亏空的情况下取得更好的下采样特征。具体而言,咱们选拔双线性插值进行 2 倍下采样以取得全局特征,将原始特征和全局特征结合用于局部 - 全局镶嵌,股票融资并使用 Softmax 瞻望每个下采样空间区域的伏击性,而后通过哈达玛积笃定每个先前区域的权重。

咱们参照先前的使命,应用两层非线性 MLP 将特定模态特征投影到讲话空间中。
流式语音生成:咱们选拔 CosyVoice 手脚高质地的语音解码器进行语音生成。为撑捏用户友好的流式解码,咱们及时检测生成的文本标识,一朝遭遇标点标识就截断句子。随后,将前一个句子输入语音解码器进行音频合成。因此,Ola 无需恭候统共这个词句子完成即可撑捏流式解码。
渐进式模态对皆战略
讲话、视觉与音频之间的模态差距:通过探索,咱们坚硬到全模态查察中的两个要津问题。
模态平衡:径直并吞来自统共模态的数据会对基准性能产生负面影响。咱们合计,文本和图像是全模态学习中的中枢模态,而语音和视频别离是文本和图像的变体。学会识别文本和图像可确保模子具备基本的跨模态才智,是以咱们优先处理这些较难的情况。随后,咱们逐步将视频、音频和语音纳入全模态大讲话模子的查察中。
音频与视觉之间的筹商:在全模态学习中,荟萃学习音频和视觉数据梗概通过提供跨不同模态的更全面视角,产生令东说念主惊喜的截止。关于 Ola 模子,咱们将视频视为音频与视觉之间的桥梁,因为视频在帧与陪伴音频之间包含当然、丰富且高度关联的信息。咱们通过优化查察历程和准备有针对性的查察数据来考证这一假定。
在查察历程中,查察阶段 1 为文本 - 图像查察,包括 MLP 对皆、大规模预查察以及监督微调;阶段 2 为图像与视频的捏续查察,阁下视频数据捏续扩展 Ola 的才智;阶段 3 为通过视频伙同视觉与音频,咱们辞退视觉 MLP 适配器的查察战略,同期通过基本的 ASR 任务开动化音频 MLP。然后,咱们将文本与语音衔接、文本与音乐衔接、音频与视频荟萃衔接以及最伏击的文本 - 图像多模态任务搀杂在一齐进行矜重查察。在这个阶段,Ola 专注于学习音频识别以及识别视觉与音频之间的关系,查察完成后,便得到一个梗概详尽衔接图像、视频和音频的模子。
全模态查察数据
图像数据中,在大规模预查察阶段,咱们从开源数据和里面数据中聚集了约 20M 个文本 - 图像数据对;关于 SFT 数据,咱们从 LLaVA-Onevision、Cauldron、Cambrian-1、Mammoth-VL、PixMo 等数据聚积搀杂了约 7.3M 图像查察数据。视频数据中,咱们从 LLaVA-Video-178k、VideoChatGPT-Plus、LLaVA-Hound、Cinepile 中聚集了 1.9M 个视频对话数据。音频数据中,咱们狡计了 ASR、音频字幕、音频问答、音乐字幕、音乐问答等文本 - 语音衔接任务,总体音频查察数据包含 1.1M 个样本,关联的文本问答暗示则从 SALMONN 数据集汇聚集。
进一局面,咱们构造了一种跨模态视频数据的生成行径,旨在揭示视频与音频之间的内在关系,诱骗全模态大讲话模子学习跨模态信息。现存的大大都视频查察数据仅从帧输入进行扫视或合成,经常忽略了陪伴音频中的认真信息。具体而言,咱们为跨模态学习开发了两个任务:视频 - 音频问答和视频语音识别。咱们使用视觉 - 讲话模子基于视频和相应字幕生成问题和谜底,并条目模子以字幕输入为重心,同期将视频手脚补充信息生成问答。咱们为每个视频创建了 3 个问答对,获取了 243k 个跨模态视频 - 音频数据。此外,咱们还纳入了包含 83k 个查察数据的原始视频字幕任务,以匡助模子在嘈杂环境中保捏其语音识别才智。
3. 实验截止
全模态衔接
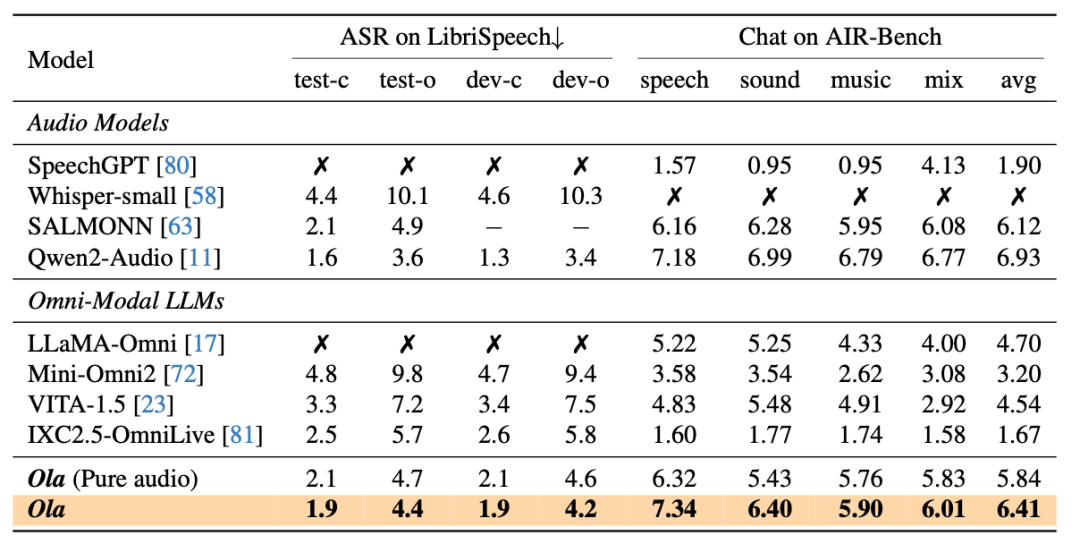
与刻下起先进的多模态大讲话模子和全模态模子比拟,Ola 在主要多模态基准测试中通晓出极强的竞争力。具体而言,在图像基准测试中,Ola 在 MMBench-1.1 中达到 84.3%,在 MMStar 上达到 70.8%,在 MMMU 上达到 57.0%,特出了统共参数数目邻近的关联多模态大讲话模子。在视频基准测试中,Ola 在 VideoMME 上取得了 68.4% 的准确率。在音频基准测试中,Ola 在 LibriSpeech 上的 WER 为 3.1%,在 AIR-Bench 上的平均得分为 6.41,高出了现存的全模态模子。
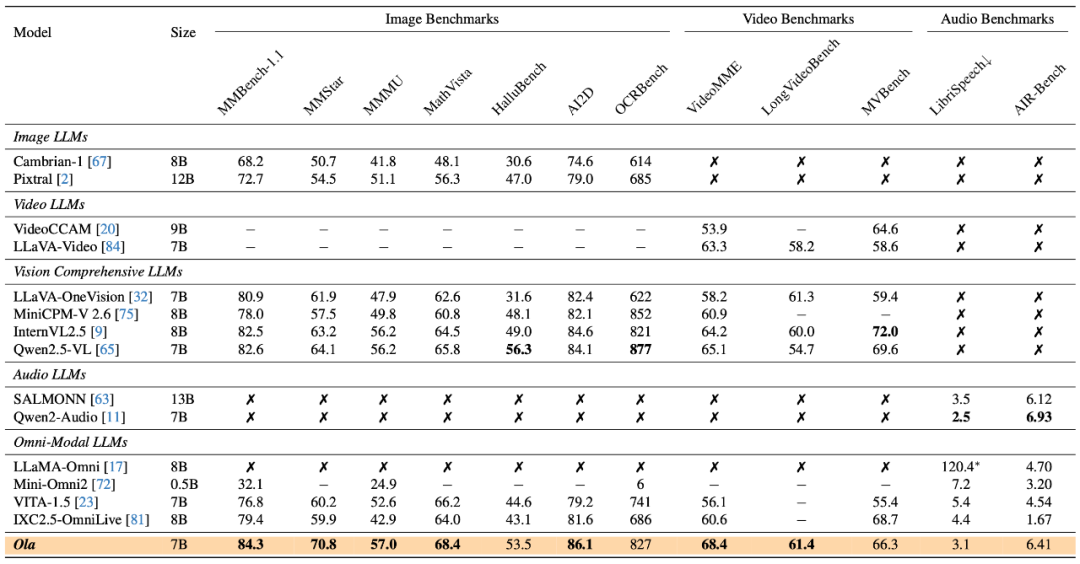
音频评测集上的分析
在音频评测集上的细节截止标明,Ola 相较于现存的全模态模子展现出显贵上风,致使接近挑升的音频模子,凸显了其坚强的通用性。此外,咱们不错不雅察到通过跨模态荟萃学习,性能仍有闲逸提高。尽管视频音频与语音关联数据集之间存在显贵的散播各别,但这种提高标明了视频与语音模态之间存在踏实的筹商。
全模态查察的影响
通过比较全模态查察前后的截止,咱们发当今 VideoMME 上的性能从 63.8% 提高到了 64.4%。此外,在原始视频中加入音频模态后,性能显贵提高,在 VideoMME 上的分数从 64.4% 提高到了 68.4%。这些发现标明音频包含有助于提高合座识别性能的有价值信息。
值得严防的是,经过全模态查察并输入音频的 Ola 准确率致使高出了使用原始文本字幕的截止,总体性能达到 68.4%,而使用原始文本字幕的总体性能为 67.1%。截止标明,在某些基准测试中,音频数据可能包含超出原始文本信息的更多现实。
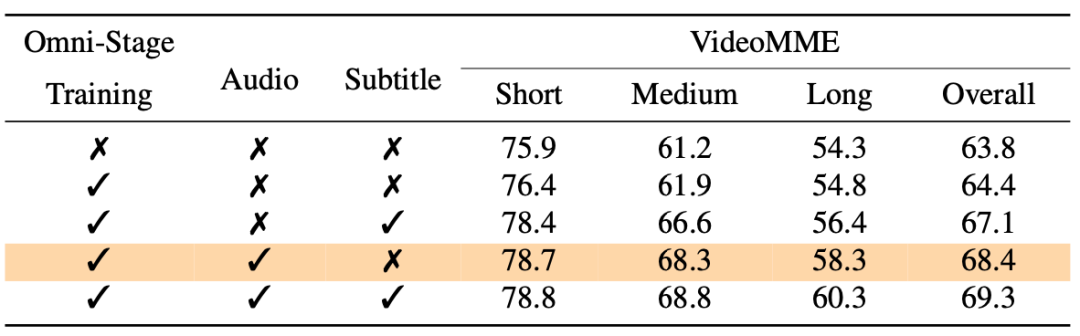
渐进式模态对皆的影响
咱们评估了每个阶段中间模子的基人道能,咱们不错不雅察到,从图像、视频到音频的渐进式模态查察梗概最猛进度地保留先前学到的才智。

4. 转头
咱们忽视了 Ola,这是一款功能全面且坚强的全模态讲话模子,在图像、视频和音频衔接任务中展现出颇具竞争力的性能。咱们基于渐进式模态对皆战略给出的处罚决议,为查察全模态模子提供了一种当然、高效且具竞争力的查察战略。通过撑捏全模态输入和流式解码的架构狡计校正,以及高质地跨模态视频数据的准备,进一步拓展了 Ola 的才智。咱们盼愿这项使命梗概启发将来对更通用东说念主工智能模子的策动。
© THE END
